为什么使用 Svelte (下)
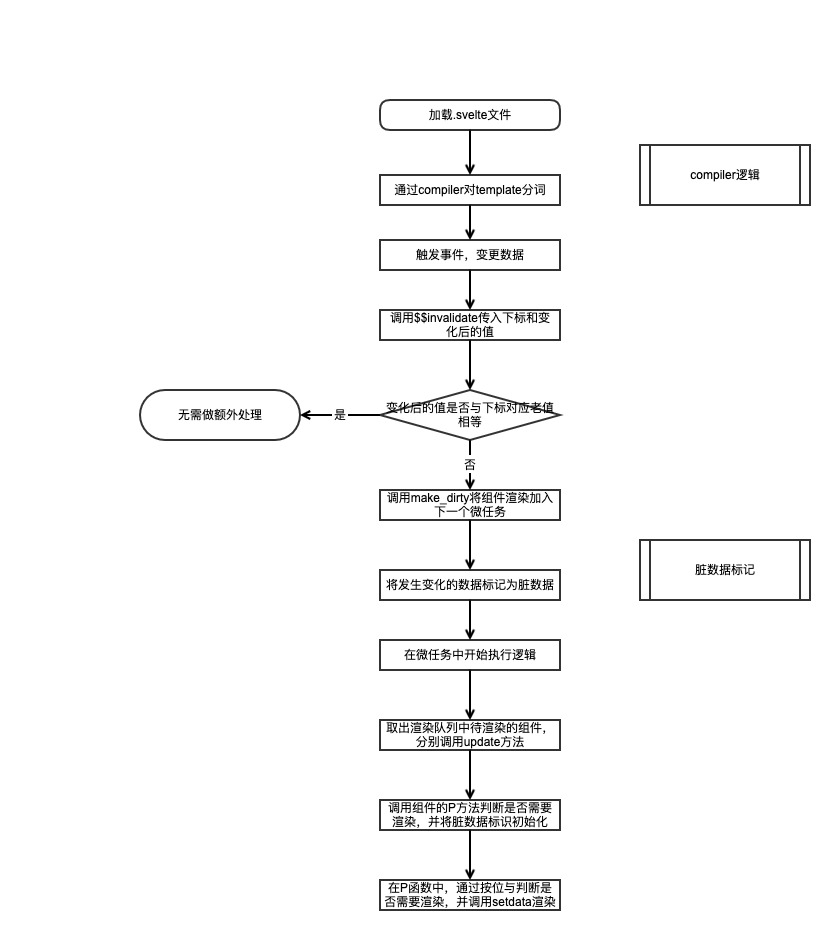
Svelte是如何判断变更的
1 | handleClick () { |
Svelte是如何标记脏数据的
1 | function make_dirty(component, i) { |
当一次性改变33个数据时,打印出来的信息是

分析一下关键语句
1 | component.$$.dirty[(i / 31) | 0] |= (1 << (i % 31)); |
将这个语句拆解一下:
1 | component.$$.dirty[(i / 31) | 0] = component.$$.dirty[(i / 31) | 0] | (1 << (i % 31)); |
(i / 31) | 0:这里是用数组下标 i 属于 31,然后向下取整(任何整数数字和 | 0 的结果都是其本身,位运算有向下取整的功效)。
(1 << (i % 31)):用 i 对 31 取模,然后做左移操作。
看到 << 右移符号,那铁定是位运算没跑了。 故而我们应该将数组转化为二进制方便我们查看
1 | component.$$.dirty.map(item => parseInt(item).toString(2)) |

那如果我只改变其中的第一项和最后一项呢

位掩码
一个比特位存放一个数据是否变化,一般1表示脏数据,0表示是干净数据。

Svelte使用位掩码(bitMask) 的技术来跟踪哪些值是脏的,即自组件最后一次更新以来,哪些数据发生了哪些更改。
JS 中所有按位运算都以 32 位二进制数执行。 有符号整数使用最左边的位作为减号
这样我们就知道了,dirty 是个数组类型,存放了多个 32 位整数,整数中的每个 bit 表示换算成 instance 数组下标的变量是否发生变更。
Svelte的更新时机
1 | // component.$$.dirty[0] 默认值为-1 |
Svelete将更新任务加入下一个微任务,在调用时,脏数据已经标记完成
Svelte在更新完脏数据后怎么使其变干净
1 | function flush() { |
Svelte是如何记录数据与DOM的对应关系的
React 和 Vue 是通过 Virtual Dom 进行 diff 来算出来更新哪些 DOM 节点效率最高。Svelte 是在编译时候,就记录了数据 和 DOM 节点之间的对应关系,并且保存在 p 函数中。也就是 Svelte 的更新方法,本质上就是一大堆if判断,逻辑非常简单
1 | p: function update(ctx, dirty) { |
这里我们关注一下if的判断条件 (dirty[0] & /count0/ 1)
&是按位与,会把两边数值转为二进制后进行比较,只有相同的二进制位都为1 才会为真。
这里的if判断条件是:拿compoenent.$.dirty1和4(4 转变为二进制是0000 0100)做按位并操作。那么我们可以思考一下了,这个按位并操作什么时候会返回1呢?
4是一个常量,转变为二进制是0000 0100, 第三位是1。那么也就是,只有dirty[0]的二进制的第三位也是1时, 表达式才会返回真。 set_data_dev(t71, ctx[33]), 更新t71这个 DOM 节点。
当我们分析到这里,已经看出了一些眉目,让我们站在更高的一个层次去看待这 30多行代码:它们其实是保存了这33个变量 和 真实DOM 节点之间的对应关系,哪些变量脏了,Svelte 会走入不同的if体内直接更新对应的DOM节点,而不需要复杂 Virtual DOM DIFF 算出更新哪些DOM节点;
这 30多行代码,是Svelte 编译了我们写的Svelte 组件之后的产物,在Svelte 编译时,就已经分析好了,数据 和 DOM 节点之间的对应关系,在数据发生变化时,可以非常高效的来更新DOM节点。
Vue 曾经也是想采取这样的思路,但是 Vue 觉得保存每一个脏数据太消耗内存了,于是没有采用那么细颗粒度,而是以组件级别的中等颗粒度,只监听到组件的数据更新,组件内部再通过 DIFF 算法计算出更新哪些 DOM 节点。Svelte 采用了比特位的存储方式,解决了保存脏数据会消耗内存的问题。
